Evolution & scaling
The Internet Computer is designed to adapt to changing demands. When more resources are needed, new subnets can be added, expanding capacity horizontally. When nodes fail, the protocol continues making progress and recovers automatically. When the protocol itself needs to improve, upgrades roll out without forks and with minimal downtime. All of this happens under governance by the Network Nervous System (NNS).
Fault tolerance
Section titled “Fault tolerance”In any large-scale distributed system, individual nodes will fail due to hardware outages, network issues, or attacks. ICP is fault-tolerant: the protocol continues making progress as long as fewer than one third of the nodes in a subnet are faulty (including Byzantine failures, where nodes behave arbitrarily rather than simply going offline).
When a node fails, the subnet continues producing blocks. The failed node can recover automatically using the state synchronization protocol. The consensus protocol is divided into epochs, each comprising several hundred consensus rounds. At the start of each epoch, all nodes create a checkpoint and a catch-up package (CUP). A CUP contains the replicated state hash and enough context for any node to resume consensus from that point. The CUP is signed by at least two thirds of the subnet’s nodes.
When a failed or newly joined node comes back online, it:
- Listens for CUP messages from peers.
- Validates the CUP (verifying the threshold signature).
- If the CUP’s state hash differs from its local state, initiates state sync to download the checkpoint.
- After syncing the checkpoint, replays the blocks produced since that CUP.
- Rejoins consensus normally.
If a node consistently lags behind or fails repeatedly, an NNS proposal can be submitted to replace it with a spare node.
Subnet recovery
Section titled “Subnet recovery”In rare cases an entire subnet can get stuck: for example, if more than one third of its nodes fail simultaneously, or if a software bug causes non-deterministic execution. In this case, the nodes cannot collectively produce a valid CUP, so automatic recovery is not possible.
Recovery requires community action: a recovery coordinator manually creates a CUP at the highest certified block height, then submits an NNS proposal containing it. If the community approves, the NNS stores the CUP in its registry. Each node’s orchestrator process detects the new CUP and restarts the replica using it, resuming from the certified state.
This governance-gated recovery process applies to regular subnets. The NNS subnet itself requires coordinated action by all NNS node providers to restart manually.
NNS canister failures
Section titled “NNS canister failures”The NNS is itself a set of canisters: root, governance, ledger, registry, and others. If one of these canisters fails due to a software bug, it can be upgraded by submitting an NNS proposal.
Each NNS canister has a controller that can upgrade it. The lifeline canister controls the root canister; the root canister controls all other NNS canisters. To upgrade a failed NNS canister, a proposal is submitted to call the root or lifeline canister’s upgrade method. If the governance canister is still functioning, this proposal follows the normal voting process. If the majority of voters approve, the failed canister is upgraded with new WebAssembly code.
For details on the NNS canister hierarchy, see System canisters.
NNS subnet failures
Section titled “NNS subnet failures”In the worst case, the subnet hosting the NNS canisters itself can fail. Because NNS governance is unavailable, the normal recovery process cannot be used. Instead, all node providers who contributed a node to the NNS subnet must manually coordinate: each provider creates a CUP and restarts their node using it.
Subnet creation
Section titled “Subnet creation”ICP scales horizontally by creating new subnets. Each subnet hosts thousands of canisters and processes messages independently. Adding a subnet adds proportional capacity to the network: more canisters, more storage, more throughput.
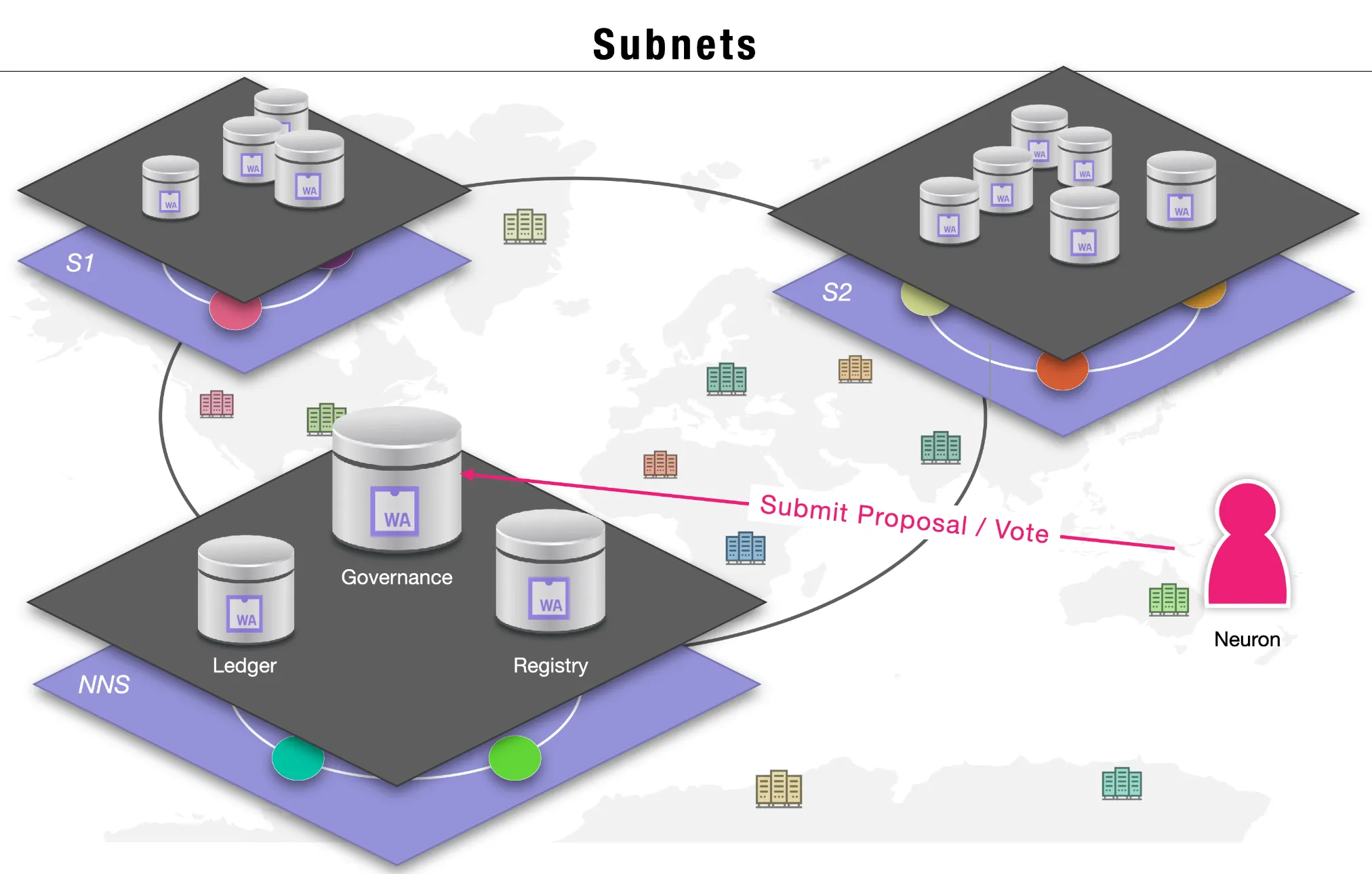
Subnets on the Internet Computer communicate using cross-subnet (XNet) messaging. A canister on any subnet can send asynchronous messages to any canister on any other subnet. XNet messages are included in the receiving subnet’s consensus blocks and authenticated using chain-key cryptography. This loosely coupled architecture means newly created subnets can immediately exchange messages with all existing subnets, without a central bottleneck.
How a new subnet is created
Section titled “How a new subnet is created”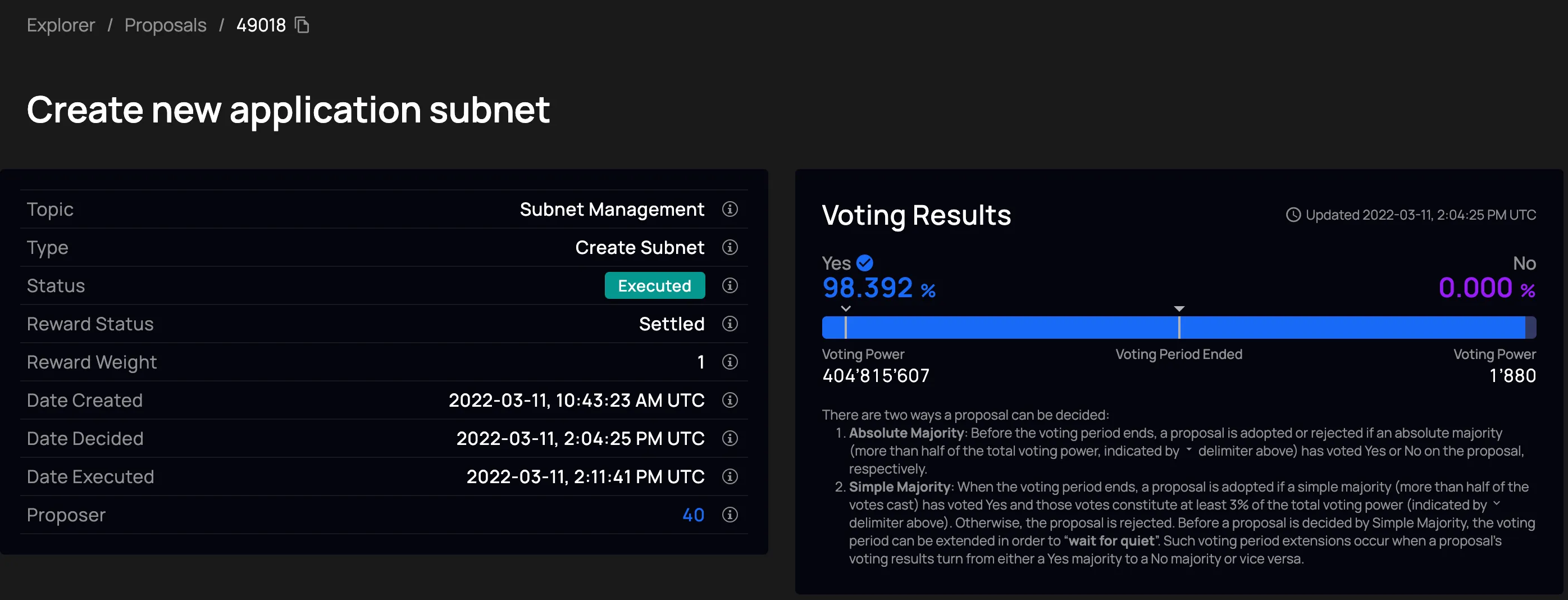
-
Onboard nodes. New nodes must be onboarded to the network first. A node provider installs IC-OS, and the node’s orchestrator registers with the NNS. The node is then available as a spare.
-
Submit a proposal. Anyone can submit an NNS proposal specifying which spare nodes should form the new subnet. The proposal includes the subnet configuration: the node list, protocol version, and other parameters.
-
Community vote. Anyone who has staked ICP can vote on the proposal. If a majority approve, the NNS registry canister records the new subnet configuration and instructs the NNS subnet to generate the initial cryptographic key material for the subnet using chain-key cryptography.
-
Subnet genesis. Each selected node’s orchestrator sees the new subnet record in the registry, downloads the correct replica software, and starts the replica with the genesis catch-up package. The nodes form the subnet and begin accepting messages.
Chain evolution
Section titled “Chain evolution”ICP upgrades its protocol approximately once per week, driven by NNS governance. These upgrades can change anything: fix bugs, add features, update algorithms, or alter the underlying technology. They are applied without forks and with minimal downtime, and the full state of all canisters is preserved across upgrades.
How protocol upgrades work
Section titled “How protocol upgrades work”The NNS registry stores the complete configuration of the Internet Computer, including the replica version each subnet should run. A version change in the registry triggers the upgrade process.

Upgrades roll out on a per-subnet basis. Within a subnet, all nodes must switch to the new protocol version simultaneously to avoid a fork. This coordination is achieved using epochs:
- The consensus protocol divides time into epochs, each several hundred rounds long.
- The first block of each epoch is a summary block containing the configuration (including replica version and cryptographic key material) for both the current epoch and the next one. Nodes therefore know the upcoming version from the start of the current epoch, not at the last moment.
- If the registry indicates a new replica version for the upcoming epoch, all nodes download it in advance.
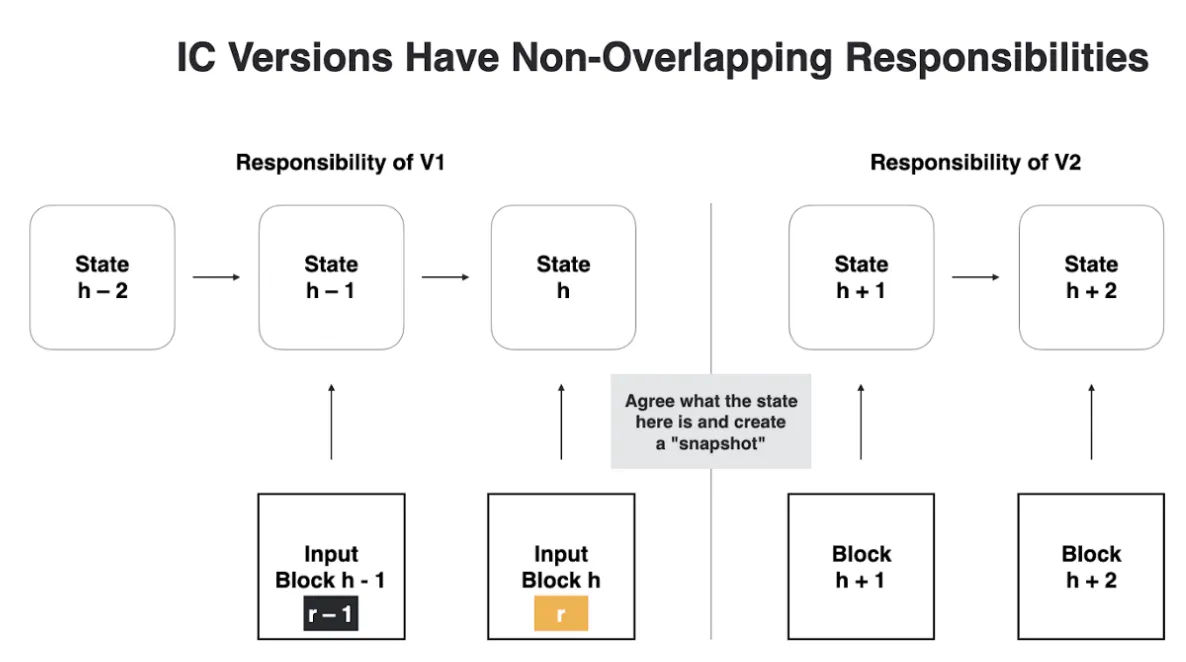
- At the epoch boundary, the nodes stop processing update calls and produce empty blocks until the summary block is finalized, executed, and the state is certified. Query calls continue normally during this pause.
- All nodes produce a CUP containing the state needed to resume at the new version, signed by more than two thirds of the subnet.
- Each node’s orchestrator receives the CUP and starts the new replica software with it as input.
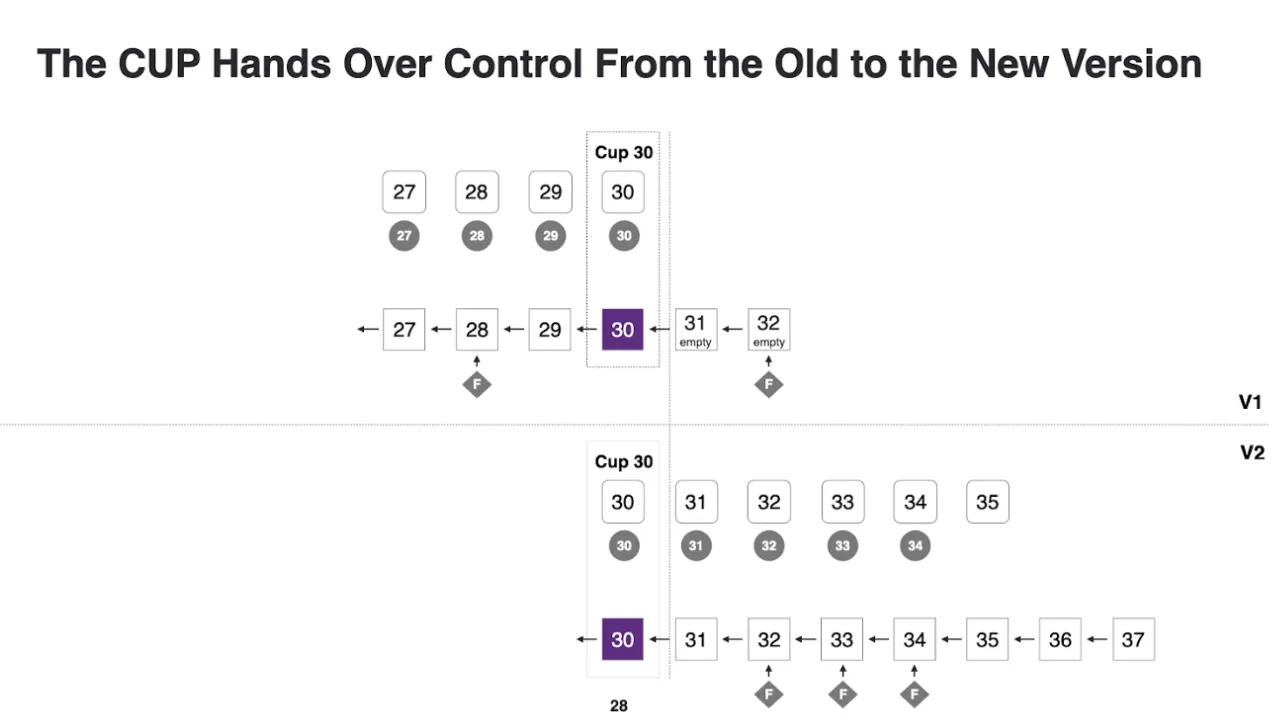
- The new replica resumes consensus immediately from the handed-off state.
Blocks and consensus artifacts are tagged with the protocol version that produced them. A replica only processes artifacts from its own version, except CUPs (which must be readable by both the pre-upgrade and post-upgrade replica).
The registry records the desired configuration, not the current running version. A subnet may continue running an older version until the CUP handoff completes. Nodes determine the actual current version by querying peers for the highest valid CUP.
Upgrade governance
Section titled “Upgrade governance”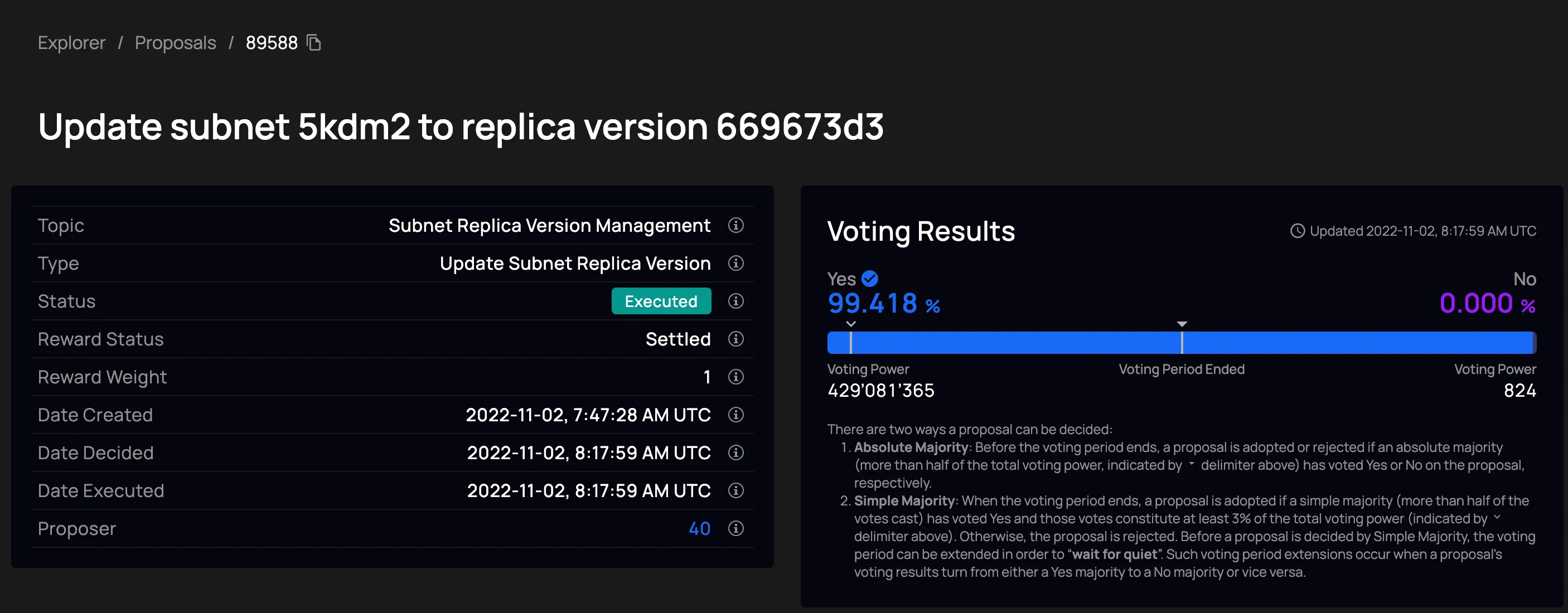
To trigger a protocol upgrade, anyone submits an NNS proposal to update the registry with a new replica version. ICP token holders who have staked their tokens can vote. If a majority approves, the registry is updated and the upgrade rolls out automatically. No hard fork or manual intervention is needed.
Further reading
Section titled “Further reading”- Chain-key cryptography: the key management underlying subnet creation and XNet messaging
- System canisters: the NNS canister hierarchy, including root, governance, ledger, registry, and lifeline
- Upgrading the Internet Computer Protocol: blog post on protocol upgrade design
- ICP whitepaper, Section 8: technical details on CUP handoff and protocol upgrades
- Video: Core protocol upgrades (10 min)
- Video: State synchronization (20 min)
- Video: Resumption (12 min)